Background | Descriptive Statistics | Inferential Statistics | Sample Size Requirements | Exercises
In a previous chapter we considered the analysis of a continuous outcome from two independent groups. In this chapter we extendt his method to consider 2 or more groups.
Illustrative Data. Let us consider ages of subjects from three centers. Data are:
Center 1: 60, 66, 65, 55, 62, 70, 51, 72, 58, 61, 71, 41, 70, 57, 55, 63, 64, 76, 74, 54, 58, 73
Center 2: 56, 65, 65, 63, 57, 47, 72, 56, 52, 75, 66, 62, 68, 75, 60, 73, 63, 64
Center 3: 67, 56, 65, 61, 63, 59, 42, 53, 63, 65, 60, 57, 62, 70, 73, 63, 55, 52, 58, 68, 70, 72, 45
The data set has 63 records (N = 63) and a grand mean of 62.1 years (standard deviation = 8.1 years).
For these data to be analyzed in Epi Info, they must be structured with two variables -- one for the dependent (outcome) variable and one for the independent (group) variable. Data for the illustrative data set are stored in AGEBYCEN.ZIP as the file AGEBYCEN.REC with variables AGE (dependent variable) and CENTER (independent variable). The first three records and last record of this data set are:
REC AGE CENTER
--- --------- -----------
1 60 1
2 66 1
3 65 1
etc.
63 45 3
Summary statistics are computed with the MEANS command:
EPI6> MEANS <DV> <IV>
where <DV> represents the dependent variable and <IV> represents the independent variable.
To compute statistics for the illustrative data, issue the commands:
EPI6> READ AGEBYCEN.REC
EPI6> MEANS AGE CENTER
This produces the following output:
MEANS of AGE for each category of CENTER
CENTER Obs Total Mean Variance Std Dev
1 22 1376 62.545 75.212 8.672
2 18 1139 63.278 60.683 7.790
3 23 1399 60.826 64.059 8.004
CENTER Minimum 25%ile Median 75%ile Maximum Mode
1 41.000 57.000 62.500 70.000 76.000 55.000
2 47.000 57.000 63.500 68.000 75.000 56.000
3 42.000 56.000 62.000 67.000 73.000 63.000
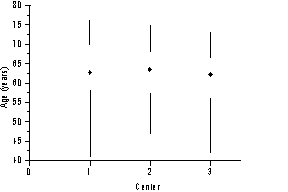
Thus, n1 = 22, n2 = 18, and n3 = 23. We also see that groups have similar means (means are 62.5, 63.3, and 60.8, respectively) and standard deviations are not too dissimilar.
Side-by-side quartile plots can be drawn (by hand) with minimal effort by graphing each group median as a dot and whiskers from the group's minimum to 25 percentile (bottom whisker) and 75 percentile to the maximum (top whisker). Click here for an example.
Inferential Statistics
Confidence Interval
s
We assume the Mean Square Within (MSW) in the ANOVA table is an pooled estimate of the common within group variance:
ANOVA
Variation SS df MS F statistic p-value
Between 66.614 2 33.307 0.497 0.616421
Within 4020.370 60 67.006
Total 4086.984 62
The standard error of the mean for group i (sei) is thus:
sei =sqrt(MSW/ ni)
with dfw = N-k, where N represents the total sample size (all groups combined) and k represents the number of groups.
For the illustrative example, se1 = sqrt(67.006 / 22) = 1.745.
A 95% confidence interval for the mean of group i (�i) is given by:
(sample mean of group i) � (tdfw,.975)(sei)
For example, a 95% confidence for the mean of group 1 = 62.5 � (t60,.025)(1.745) = 62.5 � (2.00)(1.745) = (58.9, 66.1).
The objective of ANOVA is to determine whether one or more population means of the k groups differs. The null and alternative hypotheses are:
H0: �1 = �2 = ... = �k
H1: at least one population mean differs
where �i represents the population mean of group i {i: 1, 2, . . . k}.
Briefly, ANOVA partitions the variance in the data into the variance or mea square between (MSB) and the variance or mean square (MSW). The ratio of these means squares is the F statistic:
Fstat = (MSB) / (MSW)
Under the null hypothesis, this test statistic has an F distribution with dfB = k-1 and dfW = N-k. The test is one-tailed focusing on the upper extent of the FdfB, dfw distribution. For the illustrative data set, the ANOVA table and F statistic are:
ANOVA
Variation SS df MS F statistic p-value
Between 66.614 2 33.307 0.497 0.616421
Within 4020.370 60 67.006
Total 4086.984 62
Thus, p =.62.
Assumptions: The ANOVA tests has several hidden assumptions. Traditionally, we speak of the assumption of independence, normality, and equal variance. In addition, statistical inferences assume validity of the data (i.e., freedom from selection bias and information bias) and minimal confounding.
The Kruskal-Wallis procedure is a non-parametric analogue of ANOVA. The null and alternative are:
H0: the population medians are
equal
H1: at least one population median differs
Statistics are provided in the two-variable MEANS command output:
Kruskal-Wallis One Way Analysis of Variance
Kruskal-Wallis H (equivalent to Chi square) = 0.916
Degrees of freedom = 2
p value = 0.632634
The results of this test (p = .63) provide no reason to reject H0.
Bartlett's test address whether population variances differ. The null and alternative hypotheses are:
H0: s�1 = s�2 = . . . = s�k
H1: at least one population variance differs
where s�i represents the population variance in group i. Results are provided in the output of the two-variable MEANS command. Output for the illustrative example is:
Bartlett's test for homogeneity of variance
Bartlett's chi square = 0.243 deg freedom = 2 p-value = 0.885608
Thus, for this example, c2 = 0.24 with 2 df (p = .89), providing no real evidence against the null hypothesis.
Comment: Because Bartlett's test performs poorly in non-normal populations and has poor power some statisticians advise against its routine use (Box, 1953, Biometrika, pp. 318 - 335).
We frequently want to know how large a sample is needed when testing k means. Although there is no simple answer to this question, a reasonable sample size can be determined if certain assumptions are made. Let us concern ourselves with trying to establish a significant difference among k means (via ANOVA) by asking how big a sample size is needed to (a) detect a difference between two means of D, (b) at a type I error rate of a, (c) with probability (power) 1-b. It is necessary to have a prior estimate of variability s of the outcome variable, with such estimates coming from a pilot study, prior published results, a preliminary analysis, or intuition. Computational solutions are possible once these underlying assumptions are made clear, with formulas are available in Sokal & Rohlf, 1996, pp. 263-264 (for instance). Calculations have been programmed into a the Dept of OB/GYN at the University of Hong Kong website via the URL http://department.obg.cuhk.edu.hk/ResearchSupport/Sample_size_CompMean.asp. (If this link does not take you directly to the sample size calculator, click Sample Size > Comparing Means.)
Illustrative example. Suppose we test H0: �1 = �2 = �3. Prior study suggests the measurement has s @ 8. To find a mean difference of 5, the University of Hong Kong website derives the following results.
| Type I error=0.05 | Type I error=0.01 | Type I error=0.001 | |
|---|---|---|---|
| Power=80% | 41 | 60 | 87 |
| Power=90% | 54 | 76 | 107 |
| Power=95% | 67 | 91 | 125 |
Notice that the output provides samples sizes per group (ni) at various power and alpha levels. For example, under the stated assumptions, we need n = 54 for 90% power at a = .05.
(1) ALCOHOL.ZIP: Alcohol Consumption by Income Level (Data from Monder, 1986). Data come from a survey of alcohol consumption and socioeconomic status. Data, in ALCOHOL.REC, are coded as follows:
| Variable Name | Type | Description and codes |
| ALCS | ## | Alcohol consumption score. Codes are as follows: 00 = non-drinker 01 = 1 drink per week 02 = 1-2 drinks per week 03 = 2 drinks per week 04 = 2-3 drinks per week 05 = 3 drinks per week 06 = 3-4 drinks per week 07 = 4 drinks per week 08 = 4-5 drinks per week 09 = 5 drinks per week 10 = 5-6 drinks per week 11 = 6 drinks per week 12 = 7-11 drinks per week 13 = 12+ drinks per week |
| AGE | ## | Age (in years) |
| INC | # | Income level: 1 = low, 5 = high |
(A) Univariate description of ALCS. Before performing ANOVA, describe the distribution of alcohol scores for all groups combined
(MEANS ALCS). Show the distribution of this variable in the form of a histogram (HISTOGRAM ALCS). Are data skewed? What
percentage of people in the sample are non-drinkers?
(B) ALCS by INC. Assess alcohol consumption by income.
(2) DEERMICE: Weight Gain in White-Footed Deer Mice (Hampton, 1994, p. 118, modified). Fifteen deermice are randomly assigned to one of three groups. Group A receives a standard diet, Group B receives a diet of junk food, and Group C receives a diet of health food. The research question is to determine whether WTGAIN differs by DIET. Weight gains (gms.) are as follows:
Group A: 11.8, 12.0, 10.7, 9.1, 12.1
Group B: 13.6, 14.4, 12.8, 13.0, 13.4
Group C: 9.2, 9.6, 8.6, 8.5, 9.8
(3) ROOSTER: Testosterone Levels in Roosters (Data from Hampton, 1994, p. 147). A chicken pathologist believes testosterone levels differ by rooster strain. To test this hypothesis, testosterone levels are measured in 3 strains of roosters. The research question is to determine whether testosterone levels differ by rooster strain. Data are:
REC TESTOSTERO STRAIN
--- ---------- ------
1 439 A
2 568 A
3 134 A
4 897 A
5 229 A
6 329 A
7 103 B
8 115 B
9 98 B
10 126 B
11 115 B
12 120 B
13 107 C
14 99 C
15 102 C
16 105 C
17 89 C
18 110 C
(4) MAT-ROLE.ZIP: Adaptation to Maternal Roles (Howell, 1995, pp. 302 - 304). In a study of the development of low-birthweight (LBW) infants, three groups of newborns differed in terms of birthweight and whether their mothers had participated in a training program about the special needs of low-birthweight infants. The mothers were then interviewed with the infants were 6 months old. There were three groups in the experiment: an LBW Experimental group (Group 1), an LBW Control group (Group 2), and a Full-Term Control group (Group 3). The two control groups received no special training, and so serve as a reference against which to compare the performance of the experimental intervention. The LBW Experimental group was part of the intervention program, and the researchers hoped to show that those mothers would adapt to their new role as well as the mothers of full-term infants. On the other hand, they expected mothers of LBW infants who did not receive the intervention to have some difficulty adapting. The outcome measure is an adaptation scale, whereby high values indicate some trouble adapting. (Being a parent of a low-birthweight baby is not an easy task, especially for the first few months, see Achenbach et al. 1993). Data are contained in MAT-ROLE, which can be downloaded form the server by clicking on the highlight filename, above. Download the data set and analyze these data.
{kind=link}