
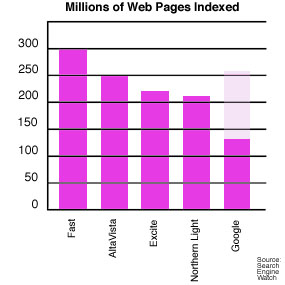
Deciding which search engine is best for you depends on a few factors. If you seek the broadest, most extensive array of sites online, you're more likely to be happy with an automated search engine. Indeed, the largest site, Fast Search boasts coverage are merely 300 million of those billion sites online. This graphic, adapted from Search Engine Watch, compares the five top rated search engines. Note that Google, a new search site, directly indexes less than 150 million sites. The rest are never actually visited by the engine.
Knowing how many hundreds of millions of sites are indexed by a particular engine may be interesting, but it is hardly helpful if you want to find quality information. Here, the notion of what "counts" online becomes paramount. Any number of people may have developed pages dedicated to the presidential race of 2000, but which ones would you cite in a paper about the contemporary political scene? An appropriate response to this question is to remember that automated search engines may be helpful in retrieving a large cache of data, but you'll probably need to examine search engines that are edited by a human being at some point. Turning to hand indexed engines like Yahoo is a good step. But Yahoo offers a relatively small number of pages and cannot vouch for the validity of their contents.
A third step is to make use of what some folks call the Invisible Web - those pages that aren't retrievable by public servers. The Invisible Web includes intranets kept behind corporate firewalls. But it also includes newspaper archives, fee-based databases, and other gold-mines of information. If you are a registered student at a college or university, you can access much of the invisible web through your library. One of the best "invisible" resources available is called Lexis Nexis. It is a web-based archive of full text newspaper articles, magazine pieces, legal documents, and other materials. No matter the physical size of your library, you have access to an impressive array of materials when you visit this site. Finding it may be a little tricky; each library organizes its electronic resources differently. But it's worth the time to discover the information available in the Invisible Web.
Activity: Visit your library's web-site and discover the electronic resources that are available from your campus. Working from a home computer, you may have to adjust the settings of your web browser to access some of these sites. Your library should offer documentation on how to set your browser so you can access their materials from off-campus.